

The fraudulent euphemism of AI thinking
An outlandishly long blog post with an uncalled-for number of pictures

I’m skeptical of reasoning models from AI companies. I’m skeptical of what these models claim to be doing versus what they are doing in a technical sense. I’m reminded of an old joke in the humanities: This is not a pipe (Figure 1).

Figure 1: The Treachery of Images by Rene Magritte (source: Wikipedia)
The main point of the joke is that the image is not a pipe. It’s an image. Representation is not the thing itself. Representation misleads. Analogies are never perfect, never one-to-one. As one critic writes,
This leads to the question – do we question the realness of objects, especially when they are presented on a two-dimensional surface? Do we forget the two-dimensional surface that merely becomes a vehicle for a two-dimensional replica based on something in real life? Do we deem the two-dimensional appearance of something as real? (de Plessis)
I find these words quite powerful for thinking about the AI reasoning models. Let’s look at what happens when you use o3, the most recent reasoning model, from OpenAI. I typed in the following prompt: “Conduct a literature review about the painting, ‘The Treachery of images’. Find multiple critical sources.” As the machine started to “reason,” the following images/words popped up on my screen:
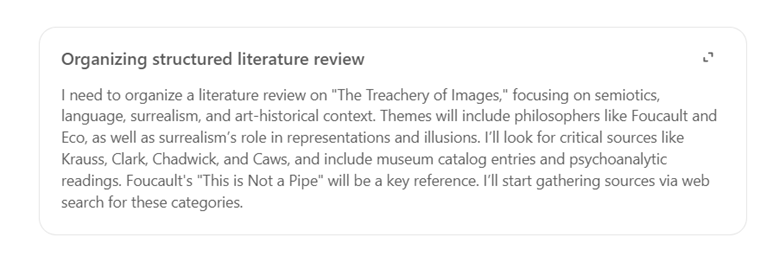

Figure 2: The “thinking” of ChatGPT’s o3 reasoning model.
Before I continue, let me say it’s rather difficult to screenshot these texts in real time because the machine types quickly only for the words to disappear just as fast. It’s jarring.[1] It’s meant to be jarring. It’s meant to be like the Wizard of Oz. Pay attention to the flames, not the dinky man behind the curtain.
This kind of rapid text generation is supposedly a narration of the model thinking. But machines don’t think. They process data via mathematical equations. So why the pomp and circumstance?
It’s all about a design choice. An aesthetic feature. As a user, I’m probably going to get bored waiting for the machine to process information, so OpenAI designers made the decision to put something on the screen to occupy my attention. It’s intentionally built to inculcate trust on the user’s part. All you need to do is watch this video from Anthropic to see the innumerable metaphors and analogies used to build your trust in these “thinking” machines. The peaceful music in the video adds to the empty rhetoric.
The reasoning behind these models is a euphemism. AI thinking (“thinking”) is a euphemism.
Let’s breakdown what the machine “thought” about:
I need to organize a literature review on "The Treachery of Images," focusing on semiotics, language, surrealism, and art-historical context. Themes will include philosophers like Foucault and Eco, as well as surrealism's role in representations and illusions. I'll look for critical sources like Krauss, Clark, Chadwick, and Caws, and include museum catalog entries and psychoanalytic readings. Foucault's "This is Not a Pipe" will be a key reference. I'll start gathering sources via websearch for these categories.
A closer look reveals volumes about this design choice. The programmers told the bot to narrate from a first person perspective. As a result, the user likely feels more connected to the machine as an agent. It uses no first names, assuming a strange level of familiarity. This might be a feature the machine has learned based on my profile. But I have no idea who Krauss, Clark, Chadwick, and Caws are. And because I don’t know who they are, the narration has a rhetorical performance of expertise. The machine almost says, “Oh, I know who know these people are. Why don’t you?”
The machine categorizes to a great degree, using lists, as I’ve written about before. Below, you can see all it is really doing is listing:
I need to organize the sources into different categories: semiotic, philosophical-linguistic, political discourse, contemporary art curation, digital culture, cognitive neuroscience, and copyright. Each category should have references and citations, specifying the author, date, argument, and significance.
As I read these sentences, I thought, “That sounds a lot like it’s just doing a google search, along with keywords.” I was curious about significance in particular, because there is no agreed upon measure of significance or impact.
I deleted this chat and started a new one, copying the exact same prompt. This time the machine wrote this:
The user is asking for a literature review on René Magritte’s painting “The Treachery of Images.” I need to track down critical sources, including academic books, journal articles, and exhibition catalogs, to ensure thorough coverage. While I could rely on prior knowledge, it’s better to browse for recent references and emerging scholarship. I’ll search for sources like Foucault’s essay, and others by Krauss, Benton, and Barthes. I'll also look into journals like Art Journal and Tate Papers for updated articles.
It was different this time. Different authors, different style. The difference is attributable to probabilistic statistics. In other words, there is uncertainty in these models. This makes the output less predictable but enables these models to respond to a wider set of queries. This is why no employers should require use of AI chatbots. Employers should think critically about if they want this kind of uncertainty with workers required to use AI.
I wanted to know what the machine was actually doing when it “thought.” Initially, I got it to give me some code about topic modeling (TF-IDF, if you were curious) and the information that it was searching Scopus. The code revealed that it was doing basic natural language processing using linguistic features. I know the machine is executing code using linear algebra. It splits the words I enter into tokens, runs some calculations, and produces a response.
A day later, I queried again about o3’s code. This time, I had the following exchange:

Figure 3: My request for the code of the o3 reasoning is flagged.
The answer was flagged. So, I revised my query and asked again, receiving the response below about proprietary issues:

Figure 4: My denied request for the code of the o3 reasoning is explained.
There is a lot going on with these responses. First, here is the evidence that the “thinking” is a design choice. The engineers at OpenAI are keeping all the operations black boxed for proprietary reasons. When these machines produce text, we can’t query them for technical explanations. With human writers, you can query them. Ask them for explanations. Now, yes, it’s true that sometimes human beings make statements we cannot explain. Sometimes, when you ask a kid why they misbehaved, they’ll just shrug and say, “I felt like it.” But when we ask a human why they wrote what they did, they can generally provide an explanation. We can’t do this with AI chatbots, at least not in a transparent way.
I want to summarize my larger point here: these chatbots have a veneer over them to hide the computational processes they execute. What they’re actually doing (linear algebra, natural language processing, some convex optimization) is hidden behind trademarks and patents. The “thinking” of these models is a euphemism. This is not a pipe. This is not reasoning.
It’s doublespeak…please allow me to clarify.
The doublespeak of AI
In George Orwell’s 1984, the main villain is Big Brother, which is a totalitarian government party that surveils the entire population. Big Brother uses doublethink and Newspeak to control the way the populus thinks about everything. Doublethink is “a process of indoctrination in which subjects are expected to simultaneously accept two conflicting beliefs as truth, often at odds with their own memory or sense of reality.” In terms of doublethink, AI companies get people to hold the belief that chatbots are smart while admitting they’re full of mistakes.
From the Wikipedia page, Newspeak is the following:
…the Party created Newspeak, which is a controlled language of simplified grammar and limited vocabulary designed to limit a person's ability for critical thinking. The Newspeak language thus limits the person's ability to articulate and communicate abstract concepts, such as personal identity, self-expression, and free will…
Doublespeak is a mashup of Newspeak and doublethink. What we are seeing with the word “reasoning” of these models is true doublespeak. It’s handwavy branding and jargon, designed to wow audiences. It’s the “great and mighty Oz” but inside of a web browser.
The same goes for the rhetoric of prompt engineering. There is no engineering going on, as my family of engineers reminds me often. OpenAI clearly uses the term engineering to latch onto vague associations with STEM fields. This gives validity to using their products.
If it isn’t already clear, I do not like the way we talk about AI chatbots. I think it hides what the machines are doing. It misleads users. Let me use an example directly from OpenAI’s prompting guide (below):

Figure 5: Example from OpenAI prompt engineering guide
On the surface, this advice seems rather harmless, yes? No. The doublespeak is so out in the open that we miss it.
There are two things missing, the first a bit more practical and the second more insidious. The first problem is that there is no explanation of why the first prompt is less effective. We’re safe to assume, from the advice, that users need to be specific, descriptive, detailed, yada, yada, yada. Be longer and you get better results.
Ah, there’s the doublespeak.
You aren’t writing. As a user, you’re getting results. When we use these machines, we aren’t interacting with language. We are querying a robot that searches its massive datasets for words similar to the words in your query. That’s why more specific or longer prompts are better: you are placing the machine in a direction for a group of words that is more related to what you’re after. When a user is more specific in their query, they place the machine into a more constrained space.
The more insidious reason has to do with the word “desired” in OpenAI’s instructions. The machine is a sycophant. A people pleaser. Ad populum. It isn’t thinking. It isn’t reasoning. It’s taking the words you give it, placing them into a vector space, and then searching for similar words and phrases in that same vector space.
Retheorizing what we’re doing with AI chatbots
Ted Underwood, a colleague of mine, has a criminally underrated article, titled “Theorizing research practices we forgot to theorize twenty years ago.” And that’s saying something because it has over 100 citations on Google scholar. It should have far, far more. In the article, Underwood argues that what we are doing when we search for things on Google or online databases is dramatically different than what we were doing in physical libraries. I want to quote him at length.
The most obvious effect of the new technology was that, like many other literary scholars in the ’90s, I found myself writing about a wider range of primary sources. But I suspect that the questions scholars posed also changed to exploit the affordances of full-text search. Before 1990, narrowly defined themes were difficult to mine: there was no Library of Congress subject heading for ‘‘descriptions of work as ‘energy’ in British Romantic-era writing.’’ Full-text search made that kind of topic ridiculously easy to explore. If you could associate a theme with a set of verbal tics, you could suddenly turn up dozens of citations not mentioned in existing scholarship and discover something that was easy to call ‘‘a discourse.’’ (p. 65-6)
A little while later, he goes on to note:
In hindsight, I underestimated the scope of the problem. It’s true that full-text search can confirm almost any thesis you bring to it, but that may not be its most dangerous feature. The deeper problem is that sorting sources in order of relevance to your query also tends to filter out all the alternative theses you didn’t bring. Search is a form of data mining, but a strangely focused form that only shows you what you already know to expect. (p. 66)
In sum, Underwood reminds us that any time we query with search, we leave out a whole panoply of potential. We are blind in a myriad of ways. Searching in terms of keywords and certain kinds of topics not only influences our research but also configures the research. The parameters of search constrain our research. It’s easy to fall into a constrained space in your own practices. Your internet habits become bounded by the search terms you use and blind to the ones you never thought to consider.
The impossibility of multidimensional space
Let’s return to AI chatbots, with Underwood’s argument in mind. When we use words to communicate with these chatbots, we aren’t doing the same verifiable thing as what we were doing when writing or searching an online database. We aren’t entering search terms into a database.
Not even close.
AI prompting masquerades as dialogue or writing. Nothing with these chatbots is dialogue or writing. When a user places a query into an AI chatbot, they lodge a point within a massive multidimensional matrix that looks sorta like this:
Figure 6: An attempt at visualizing multiple dimension space (Credit for image)
{kind=link}
Or it might look like this:

Figure 7: Another attempt as visualizing multidimensional space (Credit for image)
There is so much flabbergastingly different about these chatbots than a search engine or writing. A search such as Google retrieves information about websites. A writer is not explicitly performing any statistical analysis. And even if you were to argue with me that our brains are performing tacit statistical analysis, as some of my friends have, no human being can conceive of multidimensional space.
We cannot conceive of what these machines are doing in those multidimensions.
Let me describe why we can’t imagine multidimensional space, if you’ll permit me the digression. It involves Dr. Manhattan from one of the best graphic novels of all time, Watchmen (by Alan Moore).
Dr. Manhattan is a magnificently complex creature. He experiences his entire life at the same time. That is, he experiences time as a spatial dimension. He is, to my knowledge, the only first person omniscient narrator in all of literature.[2] There is no real way to depict this in a text-based novel or in film. Those mediums are too linear. But in a graphic novel, we get a better sense of what it is like to inhabit the 4th dimension (time) as spatiality. The panel below demonstrates this:

Figure 8: Dr Manhattan experiences his life not temporally but spatially (Credit for image)
In the 16 panels above, Manhattan experiences all panels at the same time. Moore is deliberate here. The pages contain narration telling us these panels are unfolding at the same time for Manhattan.
With Dr. Manhattan, we are only one level of multidimensional space above our own 3D existence. I can visualize the 4th dimension as time. It gets a little sticky but I can do it. I imagine an object moving through time (kinda like in Donnie Darko, if you are familiar with that movie). I can even get to the fifth dimension where the movement is the summation of all possible movements in a given time period.
What does this have to do with AI?
These AI machines go into the hundreds, thousands, or even hundreds of thousands dimensions. I can’t even imagine the 6th dimension, let alone the 60,000th dimension. To get a taste of how weird all of this math gets, here is a blog post that shows random vectors in high dimensional spaces are orthogonal. Entire dimensions are reduced to dots.
Now for my main point: any explanation of what a query is doing inside these multidimensional spaces is not only black boxed for proprietary reasons but also because these models “think” differently than humans do. (If you want the outstanding academic article that I’m drawing on here, see Jenna Burrell’s “How the machine ‘thinks’: Understanding opacity in machine learning algorithms”. I teach this article nearly every semester.)
At this point, it should be clear that saying, “Asking the chatbot” is the wrong language. Or even “querying this machine” is the wrong language. Google isn’t a librarian, ChatGPT isn’t a person, neither think.
Here is a better formulation: when you write some words into the interface of an AI machine, those words are broken down into tokens. Those tokens are placed into a massive matrix. In turn, there are calculations made. From those calculations, other tokens are identified as related. Because these companies have a ton of data, eventually the machine determines a string of words to flash on the screen for users. The machines deploy math to determine relationships between the words a user enters into the chatbot’s interface and other words it has encountered before.
Stripping away the doublespeak of AI
We need to change the way we talk about these machines. I include myself here—especially myself. We need to reorient our metaphors and analogies. Let me give it a try.
Imagine a tool that changes every time you use it. You can’t always get it to do the same task, even when you want to do so. Imagine that the tool has an internal box that you aren’t allowed to open. Even if you were to open the box, you probably wouldn’t understand it. The company that makes this tool doesn’t even understand what’s inside this box.
This is exactly what has happened with these AI chatbots. We wouldn’t exactly be excited to integrate this tool into schools or workplaces. It might be exciting to have such a tool but it would definitely waste a lot of time and resources. We certainly would not train students or workers to use it regularly.
Yet this is precisely what appears to be happening with AI chatbots. OpenAI and Anthropic have developed a set of instructions on how to use them, despite not knowing what exactly these tools are trained to do. In that video from Anthropic I linked to earlier, they literally stated, “AI models are trained and not directly programmed, so we don’t understand how they do most of the things they do.” This is an exceptionally dangerous admission: to sell a tool that you openly admit to not understanding, despite claims the machine is thinking.
We need to recognize that these machines aren’t thinking, aren’t processing information like a human being.
I want desperately to use more technical language in our discussions of these technologies. What if we said, “Use words to place the machine into a desired vector space.” Maybe that’s too parsimonious for daily use.
Honestly, I’d like the language we use to be more industrial. More mechanical. More machinic.
Conclusion: In defense of learning and working without AI
At this point, you probably think I hate AI chatbots. I don’t. I’m fascinated by their output. As a cultural artifact, these machines deserve study. I find them, too, remarkably impressive mathematically. They are technical achievements.
But they should be impressive. Companies have spent billions of dollars on training them. Companies have recruited the best programmers on earth. Countless resources have been used.
Thus, when researchers conduct empirical studies to show that human raters find AI-written essays are of better quality (whatever that means) than a high school or college student’s essay, I don’t react with surprise. Of course the document itself should be better. This is in some ways similar to saying a piece of software built by a billion-dollar tech company is better than a program built by a high schooler or college student.
A billion-dollar chatbot should be good at writing short answers. It’d be offensive if it wasn’t.
That doesn’t mean we stop having students write or stop asking workers to think for themselves about their company’s problems.
And to fend off the argument that these technologies are just calculators. The analogy of the calculator is wrong, as I argued previously. These technologies aren’t calculators. Calculators are reliable. Calculators made by different companies give you the same answers, no matter the maker. There are no multidimensional matrices using petabytes of data in a calculator.
So what’s the big deal? Why should we avoid using AI for everything (or even most things)?
Imagine a worker tasked with writing a quarterly report. They use an AI tool to draft it. It’s clean. Perfectly formatted. Perfectly performed. They set a variety of goals, including revenue targets and such. They hand it into a supervisor, someone who has many years of non-AI experience. The supervisor slowly and deliberately reads the document, growing frustrated after realizing the goals are not feasible. The report has no specific goals, nothing beyond banal suggestions that any worker at any company could generate. Worse yet, there are terms used all over the place that the employe can’t explain. When the supervisor asks about the report, the worker can’t explain any rationale behind the report.
Put bluntly, the report was written in such a vague way that it looks like a report but it’s really just a template of a report. It’s just the structure of a report without any of the important details. It lacks the thinking behind a report. There is no reasoning behind the report.
I am scared that this is what happens if we integrate these technologies into our educational system. There is room for addressing these tools while making the argument for still having students write. I don’t want students—or anyone really—to outsource their thinking to a billion dollar company.
Because writing is not always about document production. In school and the workplace, it’s often just as much about thinking carefully. It’s about communicating with people. It’s about careful thinking to communicate with people.
Endnotes
[1] I am aware that users can open these “thinking” textboxes after the machine has finished.
[2] I am indebted to my friend, Michael Gormley, for this analysis of Manhattan.
Thanks for this, John. Your conclusion reminds me a lot of some things that Hubert Dreyfus said in his early critiques of AI. You should check out his stuff if you haven't already!
Love this piece so much. I have been wanting, trying, working, all the things to articulate these ideas for quite a while now and you just did it so well here. This "Oz-like' tech is worth something; but it is a technology of 'seeming' or simulation. It is sort of simulating producing the thing; like a myth that needs to be demythologized. This idea that it can (and should) produce the thing or do the thing is not quite right; I think it can be helpful as a metacognitive co-thinking tool, but we need to be very, very careful about all the things you point to in this amazing piece. This one is spot on!